Step-by-Step Guide to Software Localization With Examples
12 min read
We recently announced Translation Memory 3.0, which, at its core, uses Elasticsearch.
This blog post will highlight particular areas of interest on what we learnt using Elasticsearch in production. Enjoy!
Elasticsearch isn’t our source-of-truth and, at least for now, that’s a good thing! During the lifetime of building Translation Memory 3.0, we’d seen many patches, videos, and interviews speaking about Elasticsearch’s ability to deal with failure. As it stands, Elasticsearch, especially in a scalable-production environment, needs a little bit of support.
Elasticsearch has introduced some really cool roles for nodes within a cluster. A node can be a Master, Worker, Data or Tribe node. Roles define a node’s responsibilities within a cluster. For example, a Worker node is responsible for receiving queries, aggregating the results, and returning them to the caller.
Master nodes are the most important when it comes to resilience. These nodes are solely responsible for managing cluster-level operations and master eligibility. To prevent a split-brain, the cluster must be able to ‘see’ a quorum of Master-eligible nodes. Therefore, nodes within a cluster containing 3 Masters (the minimum number for a quorum), can only receive requests if they are able to communicate with 2 Master-eligible nodes. This can be seen as a pessimistic approach towards the split-brain problem, but it ensures your data stays consistent across the entire cluster and nodes don’t start their own little club.
To set a node as a master, simply set these variables in your elasticsearch.yml configuration file:
node.data: false node.master: true
We use the routing parameter with all of our queries. When provided, it allows Elasticsearch to route both index and queries to a single shard, ensuring you’re not sending requests to the entire cluster. I strongly suggest you look at your data and look for appropriate routing variables (e.g. user ID, organization ID, etc.) This section assumes you’ve done the same.
If you’ve just started with Elasticsearch, then your first question is probably going to be “How many shards?”
This can’t be answered by anyone else and it requires a good deal of testing and a little bit of foresight. Each shard in Elasticsearch is a fully-fledged Lucene index. Too few or too many and you’re going to bring your cluster to a crawl. The general idea is to fire up a single-server cluster (try to use the same hardware you’re going to be using in production), add some real-world data and then start running the same kinds of queries you’ll run in production until the queries become too slow for your use-case.
At this point, you can simply divide your total amount of data by the amount in your test cluster, giving you a rough number.
However, this method will only give you the number of shards you need at that moment. If you expect your dataset to grow, then you’re also going to have to consider that rate and adjust accordingly. But ultimately, and this is something we accepted, if Elasticsearch isn’t your source-of-truth, then you have the freedom to make mistakes. If you’re of the same opinion, then make sure you use aliases with your indexes. These will ensure you can build another index in parallel and then switch your queries over once it’s complete.
It’s probably obvious, but the best thing you can do is to know your data and the queries you’ll be running over it. Elasticsearch will happily begin to accept documents from the very start without you configuring a single thing. Don’t do this. Make sure you know what it means to create an index, a document type, and the implications these decisions have on the final product.
The mapping of your documents is incredibly important, and I can’t stress enough how vital it is that you know what it means for a field to be stored, indexed and the various analysis options provided. The Elasticsearch documentation is the best place to find out about these kinds of things.
This is where we spent the most of our energy. When we started working on Translation Memory 3.0, we nailed down some hard-requirements. The most critical of these was the system’s ability to work in real-time.
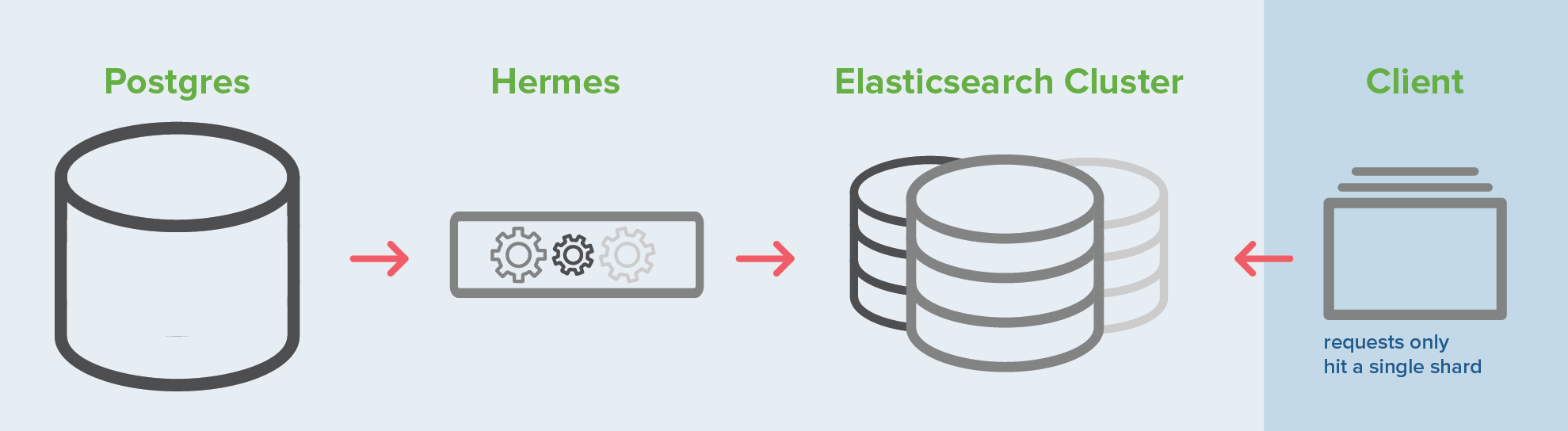
We looked at a bunch of different options but couldn’t find anything to suit our needs. We use Postgres and we wanted something which would work well with it. Around this time, we found out that the Elasticsearch River API was being deprecated and the elasticsearch-jdbc plugin didn’t suit our needs.
So, we made our own. We created a library called Hermes to asynchronously receive and process event notifications emitted by Postgres’ NOTIFY.
We’re going to be talking about the things we’ve created with Hermes in a later blog post. If you want to learn more then head over to the repository and take a look through the docs.
Designing your queries can be tricky and great care must be taken when deciding on the best approach. One thing to note when querying, however, are filters. Filters provide a way to reduce the dataset that you ultimately need to query. In addition, they can be cached for even better performance!
In our case, determining the similarity between two strings in Transifex is done using the Levenshtein distance algorithm. This algorithm, especially at scale, can be very costly. So, we save the length of each string in our index along with a bunch of other metadata. When we need to look for similar strings, we calculate the length boundaries and then filter out anything which doesn’t meet the criteria – greatly reducing the strings we actually have to perform ‘work’ over.
Marvel. I can’t recommend it enough. We used a mix of different graphing and monitoring tools but none came close to the clarity and convenience of Marvel. We used it during development and saw the value in it straight away. If your cluster is important to you and its continued running is critical to your business, then do yourself a favour and try it out!
Have you used Elasticsearch in production? What were the challenges you faced? Let us know in the comments below.