Step-by-Step Guide to Software Localization With Examples
12 min read
![]()
Our Translation Memory software (ΤΜ) is already an excellent tool that you can use for higher levels of efficiency by cutting down on both money and time spent on translations. Now it’s even better as we are introducing two new features to further reduce errors and improve quality:
So, without any further ado, let us get right into it!
If you are new to Transifex or localization, Translation Memory is an automation feature to make localization and translations, in general, easier, faster, and cheaper.
Despite its complicated technical nature, the way that it works is pretty simple. Translation Memory takes into account everything that you translate and then proceeds to automatically fill up identical translations. In that way, you won’t have to waste time and effort translating the same word or phrase repeatedly within the same project.
This feature is not to be confused with Google Translate. That’s Machine Translation – which primarily relies on AI. And while you’ve no doubt noticed that tools such as Google Translate have seen massive improvements over the years, they are still not as reliable as Translation Memory. After all, it relies so much more on user input and handmade translations, rather than AI.
As you are about to witness, Translation Memory relies on a ton of information to make automatic fill-ups as accurate as possible. Translation Memory Context and the option of only using reviewed translations are but the tip of the iceberg.
Using TM is optional. You can disable automatic fill-ups by ensuring that “Translation Memory Fill-up” is not ticked under the project settings.
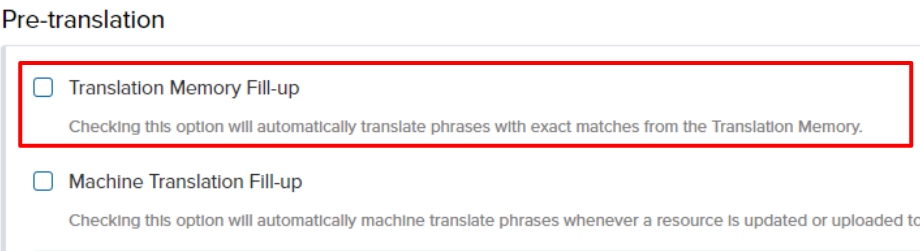
But do keep in mind that TM is going to keep on working in the background.
With that out of the way, let us take a look at our two new features for TM!
Translation Memory’s primary purpose is to automate translations by reusing past translations as much as possible. That is what software translation is mostly all about – automation.
However, translating and localizing is not just about getting the job done as quickly as you can – it’s also about doing it right. How many times have you come across wrong translations or typos while using TM? It’s certainly not a pleasant thing to behold.
That is why we are now giving you the option of telling ΤΜ to only keep translations that have already been reviewed. You can find it out under:
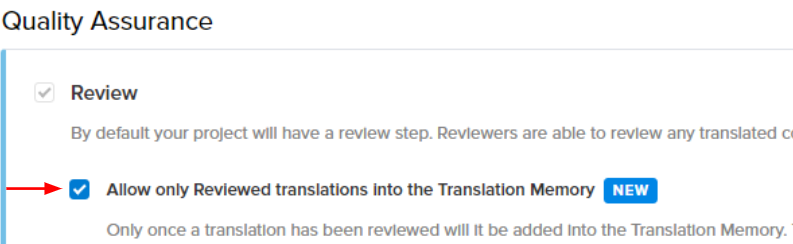
It’s a great way of getting the job done quickly yet just as accurately as you would with manual translations.
One word or phrase can have tons of meanings. And, so, it is no surprise that localization managers mostly still prefer actual translators instead of machines to get the job done.
One way for you to bridge that gap is by making Translation Memory use the context of each word or phrase. That’s how you can further reduce errors and improve the overall accuracy of TM.

For example, the word “Hello” in Greek can be used both as a greeting and farewell. But it depends on the context. So, the more context that you feed Translation Memory with, the more accurate it’s going to be.
That is one way to make translation faster and cheaper with automation tools while still maintaining accuracy.
Further Readings